Run LLMs Remotely Like a Pro: 13 Headless Tools Every Developer Should Know


Table of Content
Why You Should Be Using LLMs as Headless APIs — 5 Dev-Friendly Benefits & Use Cases
If you're a developer looking to integrate AI or LLMs to be exact into your apps without the hassle of building and managing complex frontends, here's something that might change how you work: LLMs as headless APIs.
Yep, instead of using these large language models through chatbots or web interfaces, more devs are now treating them like backend tools, silent, powerful, and ready to serve when called. And honestly? It’s a game-changer.
What Does "Headless API" Even Mean?
In simple terms, a headless API means you’re using the brain (the model) without the face (the UI). Think of it like using a weather API, you don’t care what the website looks like; you just want the data. Same with an LLM: you send a prompt, get a response, and do whatever you want with it in your app.
No interface. No fluff. Just raw, smart power.
 Hazem Abbas
Hazem Abbas
Why Bother Going Headless?
Because flexibility, scalability, and control matter. Here are some real-world benefits I’ve personally used (and loved):
1. Plug Into Any App You Build
You can drop a headless LLM into any project, from internal tools to customer-facing dashboards. Whether it's summarizing content, auto-generating code comments, or powering chat features, the sky's the limit.
This will save you time from building your own system from scratch, and even more, production-ready app.
2. Keep Your Stack Clean
Do not complicate things!
Using a headless setup keeps your frontend light. Let the LLM handle NLP tasks while your app focuses on UX and logic. No need to bloat your client-side with AI stuff.
3. Easy Scaling
If you scale you progress!
Since it's API-based, scaling is straightforward. Got more users? Add load balancers or rate-limited proxies. Done.
4. Better Security (When Done Right)
By keeping the LLM behind your backend, you avoid exposing sensitive prompts or keys directly to the browser. Always proxy, never expose, golden rule.
5. Custom Logic + Guardrails
Want to filter harmful content or format outputs exactly how you like? With a headless approach, you can wrap the LLM in your own logic before sending results to the user.
 Hazem Abbas
Hazem Abbas
Real-World Use Cases That’ll Make You Go “Oh Yeah!”
- Auto-generate documentation based on codebases.
- Personalize email campaigns at scale.
- Build smart support bots for your app or site.
- Enhance search bars with natural language understanding.
- Create dynamic forms that adapt based on user input.
Personally, I perfere to use LMStudio Headless API for local development and local automation tasks, but hey, there are dozens of other free open-source solutions, that we will list here.
1- LLM API
LLM-API is a developer-friendly tool that brings the power of Large Language Models (LLMs) directly to your machine. With support for models like Llama, Alpaca, Vicuna, Mistral, and more, as It is running on CPUs or GPU-accelerated setups, it offers flexibility and performance. Just define your model in a simple YAML config, and LLM-API handles the rest: auto-downloading, running locally, and exposing a clean OpenAI-style API.
You can use it with Python clients, LangChain integrations, or Docker, perfect for devs, researchers, and AI enthusiasts who want full control without the cloud hassle. Run cutting-edge LLMs right from your own hardware.
 1b5d
1b5d2- Crawl4AI
Crawl4AI is the fastest, most developer-friendly web crawler built for LLMs and AI agents.
It’s open-source, lightning-fast, and packed with smart features like Markdown generation, structured extraction, browser control, and Docker-ready deployment. Perfect for RAG pipelines, data scraping, and real-time AI workflows, all with a sleek CLI and Python support.
If you are looking for something reliable and battle tested then use Crawl4AI.
Crawl4AI Features
- Blazing-fast LLM-ready crawling
- Clean Markdown & structured data
- Browser automation & stealth mode
- Docker & CLI support
- Smart extraction & error handling
- Open source, no API keys required
- Quick install if you are using Python
- (Docker) Browser pooling with page pre-warming for faster response times
- (Docker) Interactive playground to test and generate request code
- (Docker) MCP integration for direct connection to AI tools like Claude Code
- (Docker) Comprehensive API endpoints including HTML extraction, screenshots, PDF generation, and JavaScript execution
- (Docker) Multi-architecture support with automatic detection (AMD64/ARM64)
- (Docker) Optimized resources with improved memory management
 unclecode
unclecode3- WebLLM
WebLLM is an amazing open-source app that lets you run powerful language models directly in the browser, no server needed. It uses WebGPU for fast, local inference and supports the OpenAI API, so you can plug in open-source models easily.
It is perfect for privacy-focused apps, AI assistants, or adding smart features to your web projects without backend hassle. Great for developers looking to ship fast with zero dependencies.
WebLLM runs LLMs directly in the browser using WebGPU for fast, local inference. No server? No problem. It supports OpenAI-style API calls with streaming, JSON output, and custom model integration.
You can deploy it via NPM, Yarn, or CDN, and run models in worker threads to keep your UI smooth. Works with Chrome extensions and is perfect for chatbots, AI tools, and privacy-first apps.
Supported Models :
Llama 3, Llama 2, Phi 3, Gemma-2B, Mistral-7B, Qwen2 (0.5B–7B), and more via MLC.
 mlc-ai
mlc-ai4- LLM API
LLM API is an open-source self-hosted free app that provides a clean, typed interface for working with OpenAI, Anthropic, and Azure chat models across browser, edge, and Node.js environments.
It handles errors, rate limits, and token overflow automatically, and works great with tools like zod-gpt for structured outputs.
 dzhng
dzhng5- Skyvern
Although, it is not an actual headless API for LLM, Skyvern automates browser tasks using LLMs and computer vision, offering a simple API to handle complex workflows across websites. Unlike fragile scripts that break with site updates, Skyvern uses AI to interact with pages more reliably.
It’s great for scaling automation without the hassle of constant maintenance.
 Skyvern-AI
Skyvern-AI6- LiteLLM
LiteLLM lets you call any LLM API (OpenAI, Azure, Hugging Face, and more) using the OpenAI format, all with consistent responses, retries, and budget controls. It also offers a proxy server for managing multiple models, rate limits, and deployments at scale.
 BerriAI
BerriAI7- OpenLLM: Self-Hosting LLMs Made Easy
OpenLLM makes it simple to run any open-source LLM — like Llama 3.3, Qwen2.5, Phi3, and more, as an OpenAI-compatible API with just one command. It comes with a built-in chat UI, powerful inference backends, and easy deployment options for Docker, Kubernetes, or BentoCloud, so you can build and scale enterprise-grade AI apps fast.
Supported Models
OpenLLM supports a wide range of open-source models including: Llama 3.1 (8B), Llama 3.2 (1B), Llama 3.3 (70B), Llama 4 (17B 16E), Gemma2 (2B), Gemma3 (3B), Mistral (8B), Mistral Large (123B), Phi4 (14B), Pixtral (12B), Qwen2.5 (7B), Qwen2.5-Coder (3B), QwQ (32B), and DeepSeek (671B). You can also bring your own model for custom use cases.
 bentoml
bentoml8- Langchain LLM API
A LangChain-compatible interface for integrating with LLM-API, letting you use any locally running model seamlessly in your LangChain workflows.
Just install with pip install langchain-llm-api, then connect to your local LLM-API server and start using models with full support for prompts, streaming, and embeddings.
 1b5d
1b5d9- LLM Sherpa
LLM Sherpa is an open-source tool that helps developers extract clean, structured text from PDFs and other documents — perfect for building better RAG pipelines. It understands layout, headings, paragraphs, tables, and even removes watermarks or footers.
With support for OCR and a range of file types like DOCX, PPTX, and HTML, it’s ideal for preparing high-quality data for LLMs. Run it locally with Docker and get the most out of your documents for AI workflows.
 nlmatics
nlmatics10- EricLLM
Eric is a free, fast, lightweight API for serving LLMs with real-time batching and performance tweaks. Supports features like LoRA, 8-bit cache, custom stop tokens, and multi-GPU setups — built for developers who want speed and flexibility.
Great for local deployments, with active improvements for better generation control and efficiency. Run it yourself and tweak models to your heart’s content.
 epolewski
epolewski11- llm-api
LLM-API is a lightweight HTTP API for running LLMs locally with support for GGUF models via llama.cpp. Offers /predict and /chat endpoints for easy integration, with basic parameter control and plain text responses. Great for developers experimenting with local LLM inference.
Note, it is still in development, not production-ready.
 cmitsakis
cmitsakis12- MLC LLM
MLC LLM is an open-source universal LLM deployment engine that compiles and runs AI models across GPUs and platforms, from NVIDIA to Apple Silicon, web browsers to mobile.
It uses MLCEngine for high-performance inference with OpenAI-compatible APIs in Python, JS, iOS, Android, and more. Build once, run anywhere, all powered by a community-driven compiler stack.
 mlc-ai
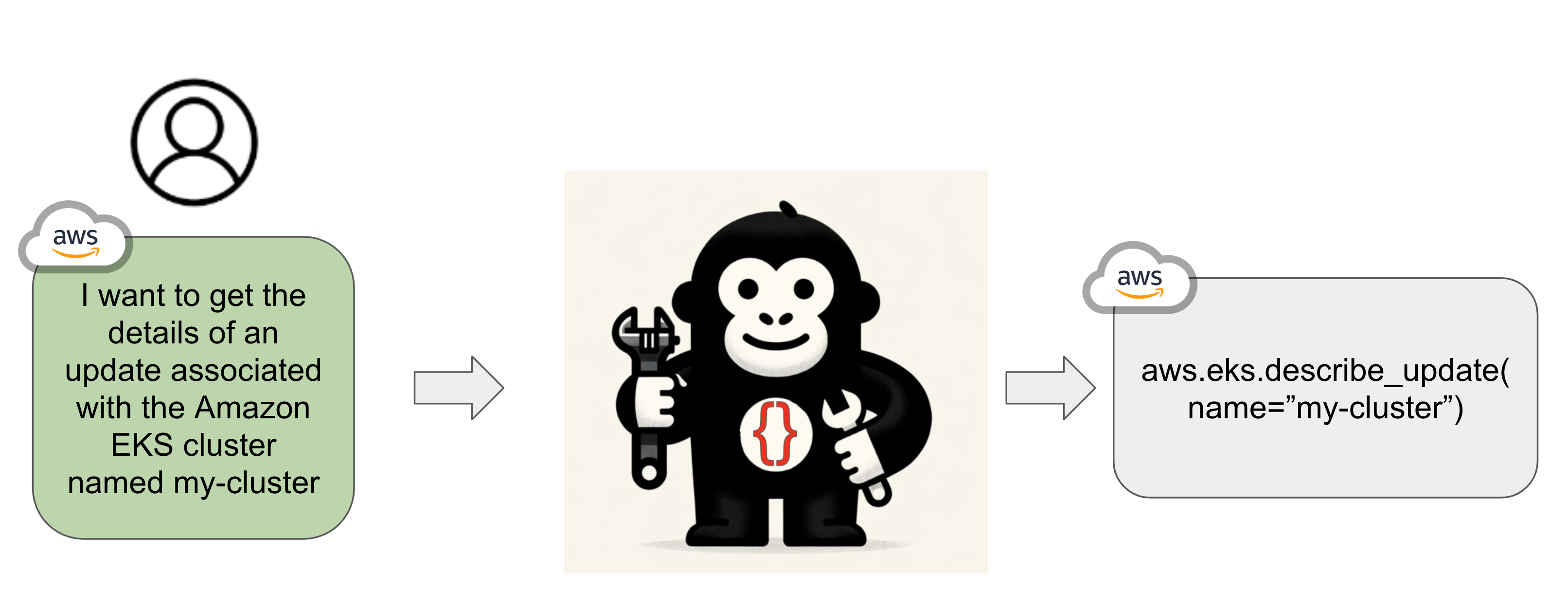
mlc-ai13- Gorilla: Large Language Model Connected with Massive APIs
Gorilla is a powerful research project from UC Berkeley that connects large language models with real-world tools and services via API calls.
It enables LLMs to perform function calls, execute code, and interact with external systems, pushing the boundaries of autonomous AI agents. With support for parallel and multi-language functions, Gorilla sets new standards in open-source LLM performance.
Final Thoughts
Treating LLMs as headless APIs isn’t just a trend, it’s a smarter way to build. It gives developers more control, cleaner integrations, and opens up endless possibilities.
And if you're worried about AI detection (especially from Google), this method helps fly under the radar since the AI-generated content is processed server-side and wrapped in your own logic.
So next time you're building something cool, think of LLMs not as assistants, but as tools — invisible, powerful, and always ready to help you ship smarter apps.
 Hazem Abbas
Hazem Abbas